 ShardingSphere_高性能架构模式
ShardingSphere_高性能架构模式
# 第01章 高性能架构模式
互联网业务兴起之后,海量用户加上海量数据的特点,单个数据库服务器已经难以满足业务需要,必须考虑数据库集群的方式来提升性能。高性能数据库集群的第一种方式是“读写分离”,第二种方式是“数据库分片”。
# 1、读写分离架构
读写分离原理:读写分离的基本原理是将数据库读写操作分散到不同的节点上,下面是其基本架构图:
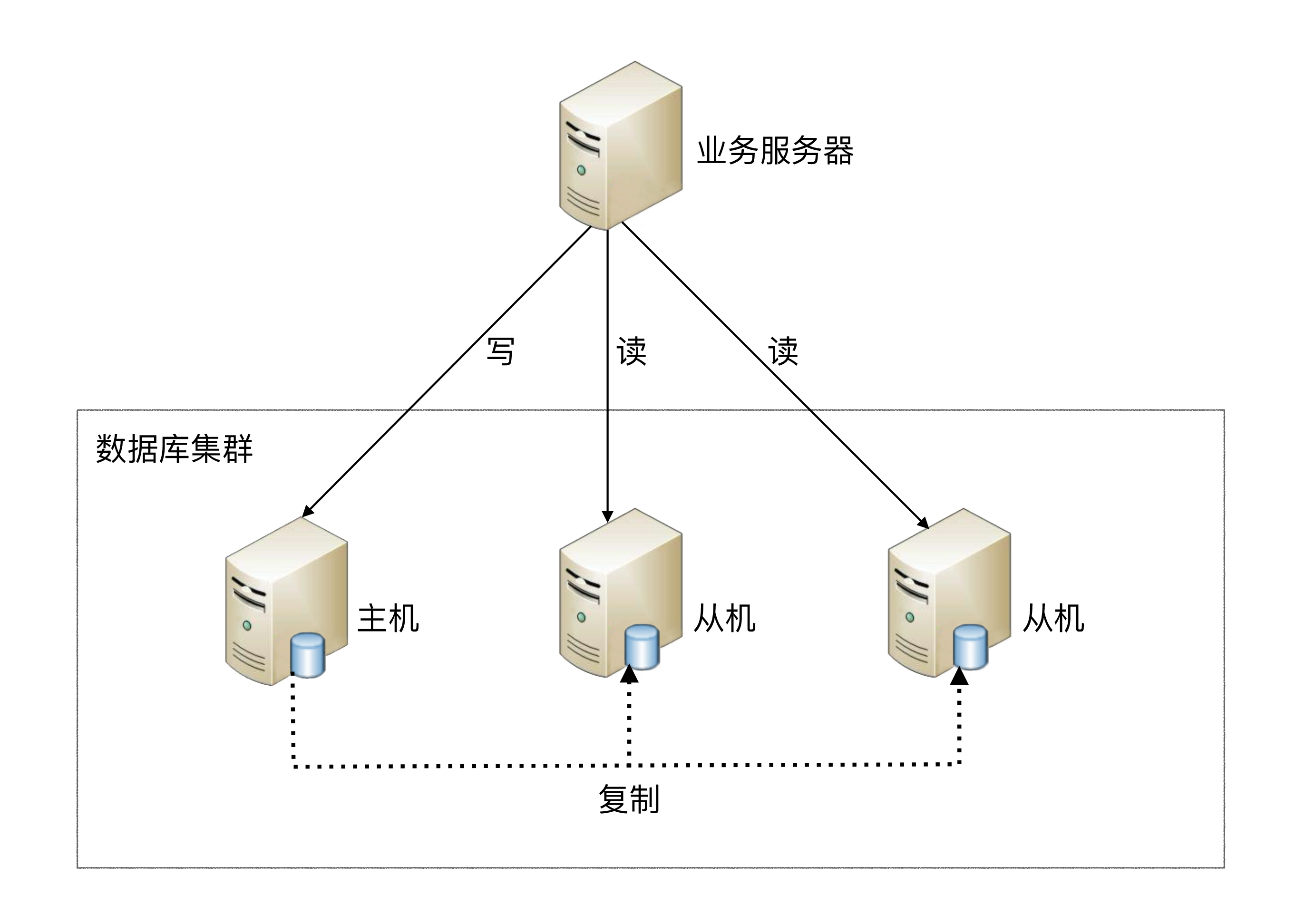
读写分离的基本实现:
主库负责处理事务性的增删改操作,从库负责处理查询操作,能够有效的避免由数据更新导致的行锁,使得整个系统的查询性能得到极大的改善。- 读写分离是
根据 SQL 语义的分析,将读操作和写操作分别路由至主库与从库。 - 通过
一主多从的配置方式,可以将查询请求均匀的分散到多个数据副本,能够进一步的提升系统的处理能力。 - 使用
多主多从的方式,不但能够提升系统的吞吐量,还能够提升系统的可用性,可以达到在任何一个数据库宕机,甚至磁盘物理损坏的情况下仍然不影响系统的正常运行。
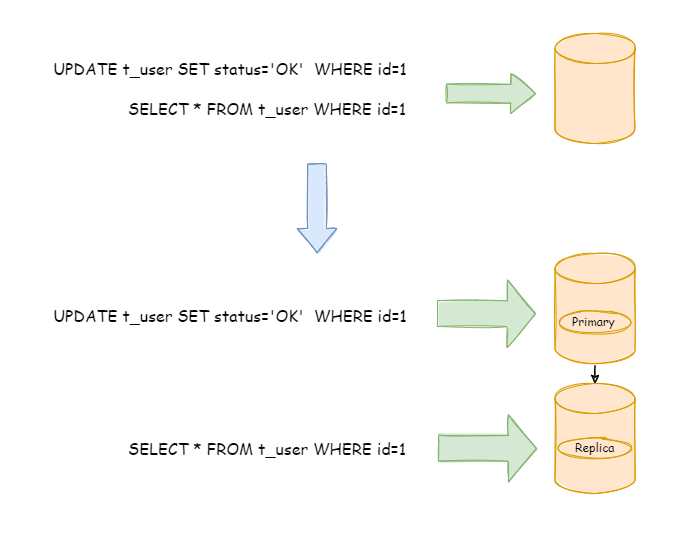
下图展示了根据业务需要,将用户表的写操作和读操路由到不同的数据库的方案:
CAP 理论:
CAP 定理(CAP theorem)又被称作布鲁尔定理(Brewer's theorem),是加州大学伯克利分校的计算机科学家埃里克·布鲁尔(Eric Brewer)在 2000 年的 ACM PODC 上提出的一个猜想。对于设计分布式系统的架构师来说,CAP 是必须掌握的理论。
在一个分布式系统中,当涉及读写操作时,只能保证一致性(Consistence)、可用性(Availability)、分区容错性(Partition Tolerance)三者中的两个,另外一个必须被牺牲。
- C 一致性(Consistency):对某个指定的客户端来说,读操作保证能够返回最新的写操作结果
- A 可用性(Availability):非故障的节点在合理的时间内返回合理的响应
(不是错误和超时的响应) - P 分区容忍性(Partition Tolerance):当出现网络分区后
(可能是丢包,也可能是连接中断,还可能是拥塞),系统能够继续“履行职责”
CAP特点:
在实际设计过程中,每个系统不可能只处理一种数据,而是包含多种类型的数据,
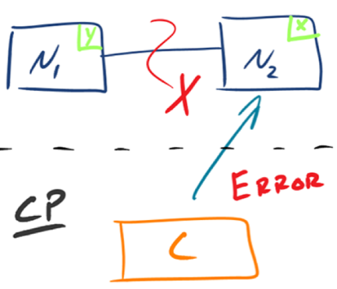
有的数据必须选择 CP,有的数据必须选择 AP,分布式系统理论上不可能选择 CA 架构。CP:如下图所示,
为了保证一致性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 需要返回 Error,提示客户端 C“系统现在发生了错误”,这种处理方式违背了可用性(Availability)的要求,因此 CAP 三者只能满足 CP。
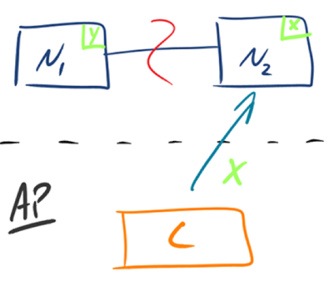
- AP:如下图所示,
为了保证可用性,当发生分区现象后,N1 节点上的数据已经更新到 y,但由于 N1 和 N2 之间的复制通道中断,数据 y 无法同步到 N2,N2 节点上的数据还是 x。这时客户端 C 访问 N2 时,N2 将当前自己拥有的数据 x 返回给客户端 C 了,而实际上当前最新的数据已经是 y 了,这就不满足一致性(Consistency)的要求了,因此 CAP 三者只能满足 AP。注意:这里 N2 节点返回 x,虽然不是一个“正确”的结果,但是一个“合理”的结果,因为 x 是旧的数据,并不是一个错乱的值,只是不是最新的数据而已。
CAP 理论中的
C 在实践中是不可能完美实现的,在数据复制的过程中,节点N1 和节点 N2 的数据并不一致(强一致性)。即使无法做到强一致性,但应用可以采用适合的方式达到最终一致性。具有如下特点:- 基本可用(Basically Available):分布式系统在出现故障时,允许损失部分可用性,即保证核心可用。
- 软状态(Soft State):允许系统存在中间状态,而该中间状态不会影响系统整体可用性。这里的中间状态就是 CAP 理论中的数据不一致。
最终一致性(Eventual Consistency):系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。
# 2、数据库分片架构
读写分离的问题:
读写分离分散了数据库读写操作的压力,但没有分散存储压力,为了满足业务数据存储的需求,就需要将存储分散到多台数据库服务器上。
数据分片:
将存放在单一数据库中的数据分散地存放至多个数据库或表中,以达到提升性能瓶颈以及可用性的效果。 数据分片的有效手段是对关系型数据库进行分库和分表。数据分片的拆分方式又分为垂直分片和水平分片。
# 2.1、垂直分片
垂直分库:
按照业务拆分的方式称为垂直分片,又称为纵向拆分,它的核心理念是专库专用。 在拆分之前,一个数据库由多个数据表构成,每个表对应着不同的业务。而拆分之后,则是按照业务将表进行归类,分布到不同的数据库中,从而将压力分散至不同的数据库。

下图展示了根据业务需要,将用户表和订单表垂直分片到不同的数据库的方案:
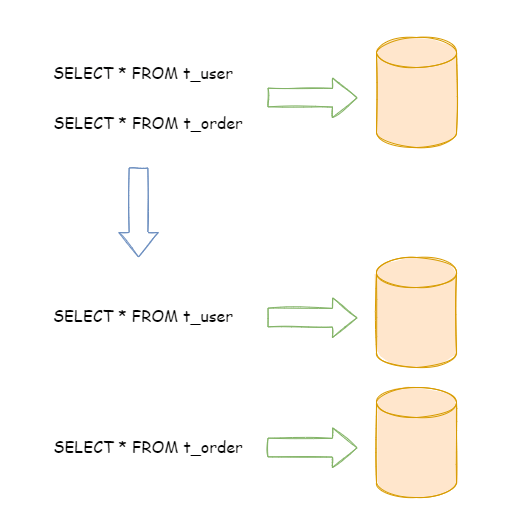
垂直拆分可以缓解数据量和访问量带来的问题,但无法根治。如果垂直拆分之后,表中的数据量依然超过单节点所能承载的阈值,则需要水平分片来进一步处理。
垂直分表:
垂直分表适合将表中某些不常用的列,或者是占了大量空间的列拆分出去。
假设我们是一个婚恋网站,用户在筛选其他用户的时候,主要是用 age 和 sex 两个字段进行查询,而 nickname 和 description 两个字段主要用于展示,一般不会在业务查询中用到。description 本身又比较长,因此我们可以将这两个字段独立到另外一张表中,这样在查询 age 和 sex 时,就能带来一定的性能提升。
垂直分表引入的复杂性主要体现在表操作的数量要增加。例如,原来只要一次查询就可以获取 name、age、sex、nickname、description,现在需要两次查询,一次查询获取 name、age、sex,另外一次查询获取 nickname、description。
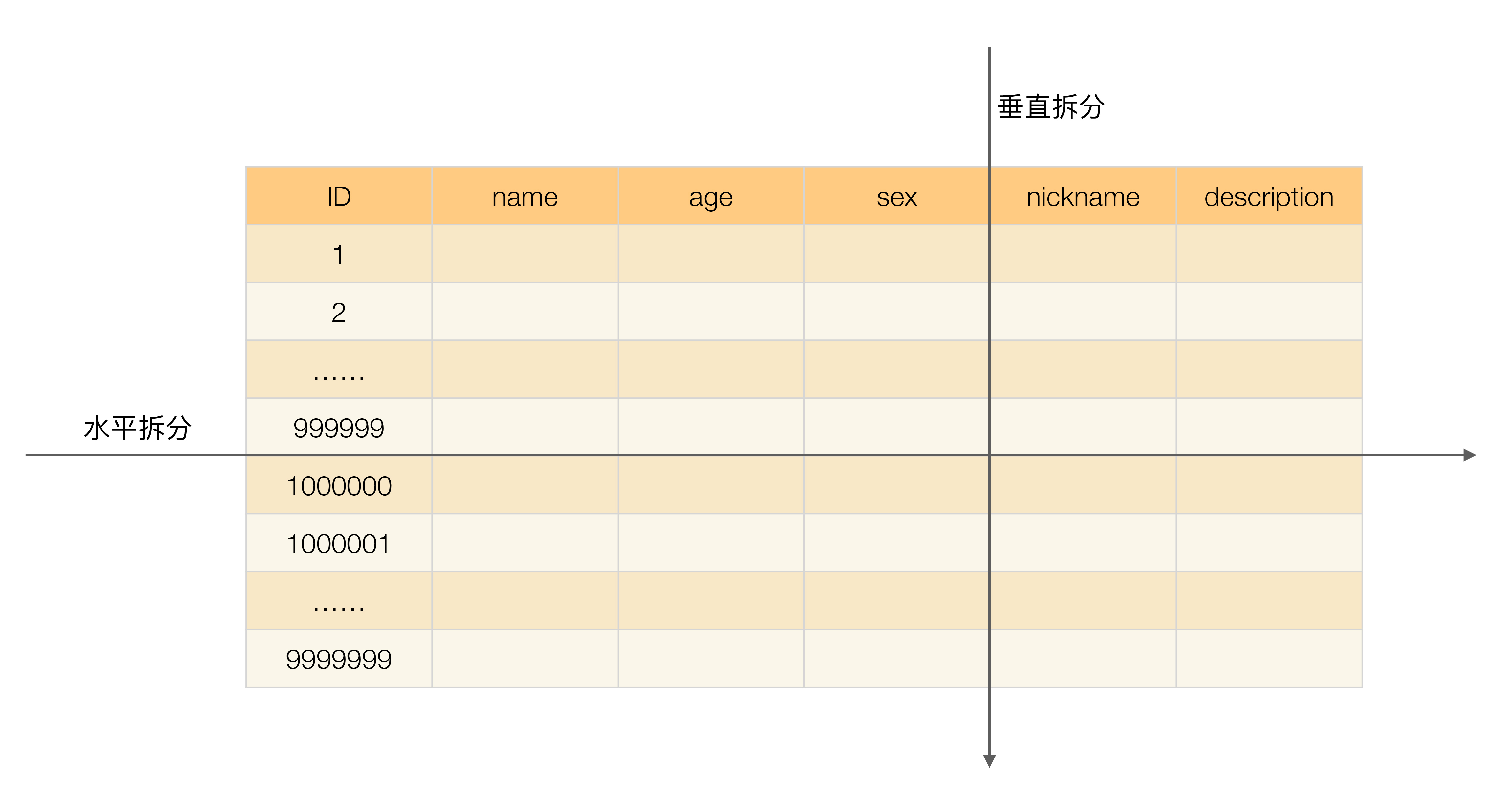
水平分表适合表行数特别大的表,水平分表属于水平分片。
# 2.2、水平分片
水平分片又称为横向拆分。 相对于垂直分片,它不再将数据根据业务逻辑分类,而是通过某个字段(或某几个字段),根据某种规则将数据分散至多个库或表中,每个分片仅包含数据的一部分。 例如:根据主键分片,偶数主键的记录放入 0 库(或表),奇数主键的记录放入 1 库(或表),如下图所示。
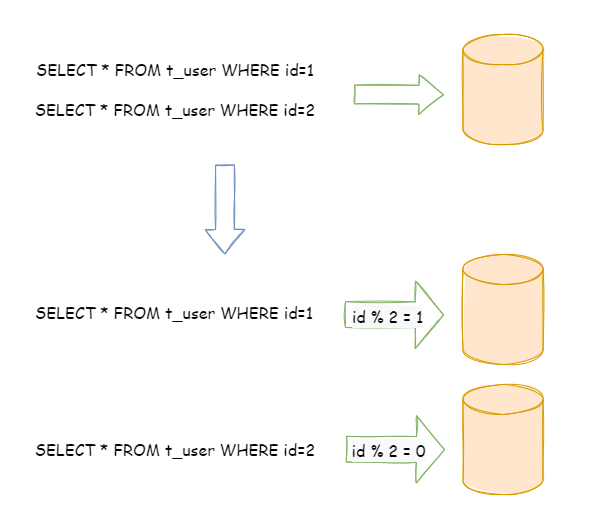
单表进行切分后,是否将多个表分散在不同的数据库服务器中,可以根据实际的切分效果来确定。
**水平分表:**单表切分为多表后,新的表即使在同一个数据库服务器中,也可能带来可观的性能提升,如果性能能够满足业务要求,可以不拆分到多台数据库服务器,毕竟业务分库也会引入很多复杂性;
**水平分库:**如果单表拆分为多表后,单台服务器依然无法满足性能要求,那就需要将多个表分散在不同的数据库服务器中。
阿里巴巴Java开发手册:
【推荐】单表行数超过 500 万行或者单表容量超过 2GB,才推荐进行分库分表。
说明:如果预计三年后的数据量根本达不到这个级别,
请不要在创建表时就分库分表。
# 3、读写分离和数据分片架构
下图展现了将数据分片与读写分离一同使用时,应用程序与数据库集群之间的复杂拓扑关系。
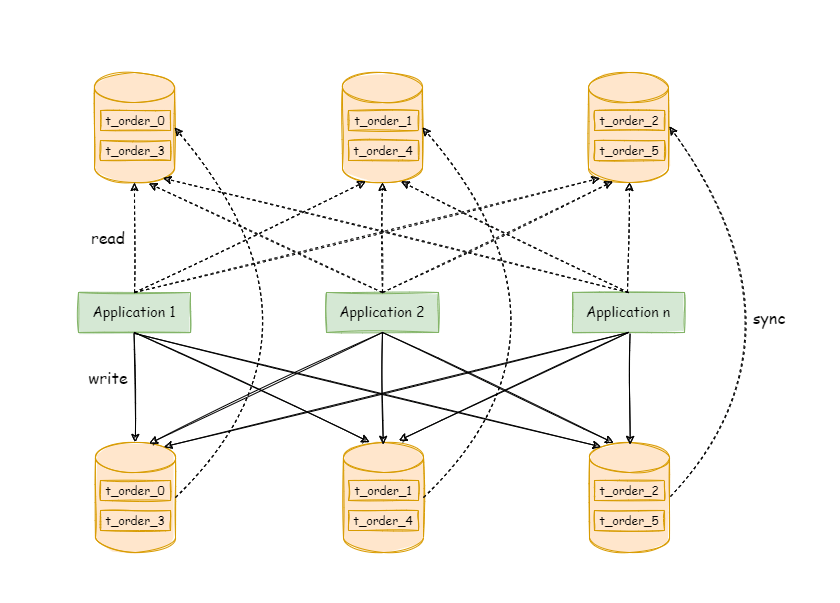
# 4、实现方式
读写分离和数据分片具体的实现方式一般有两种: 程序代码封装和中间件封装。
# 4.1、程序代码封装
程序代码封装指在代码中抽象一个数据访问层(或中间层封装),实现读写操作分离和数据库服务器连接的管理。
**其基本架构是:**以读写分离为例

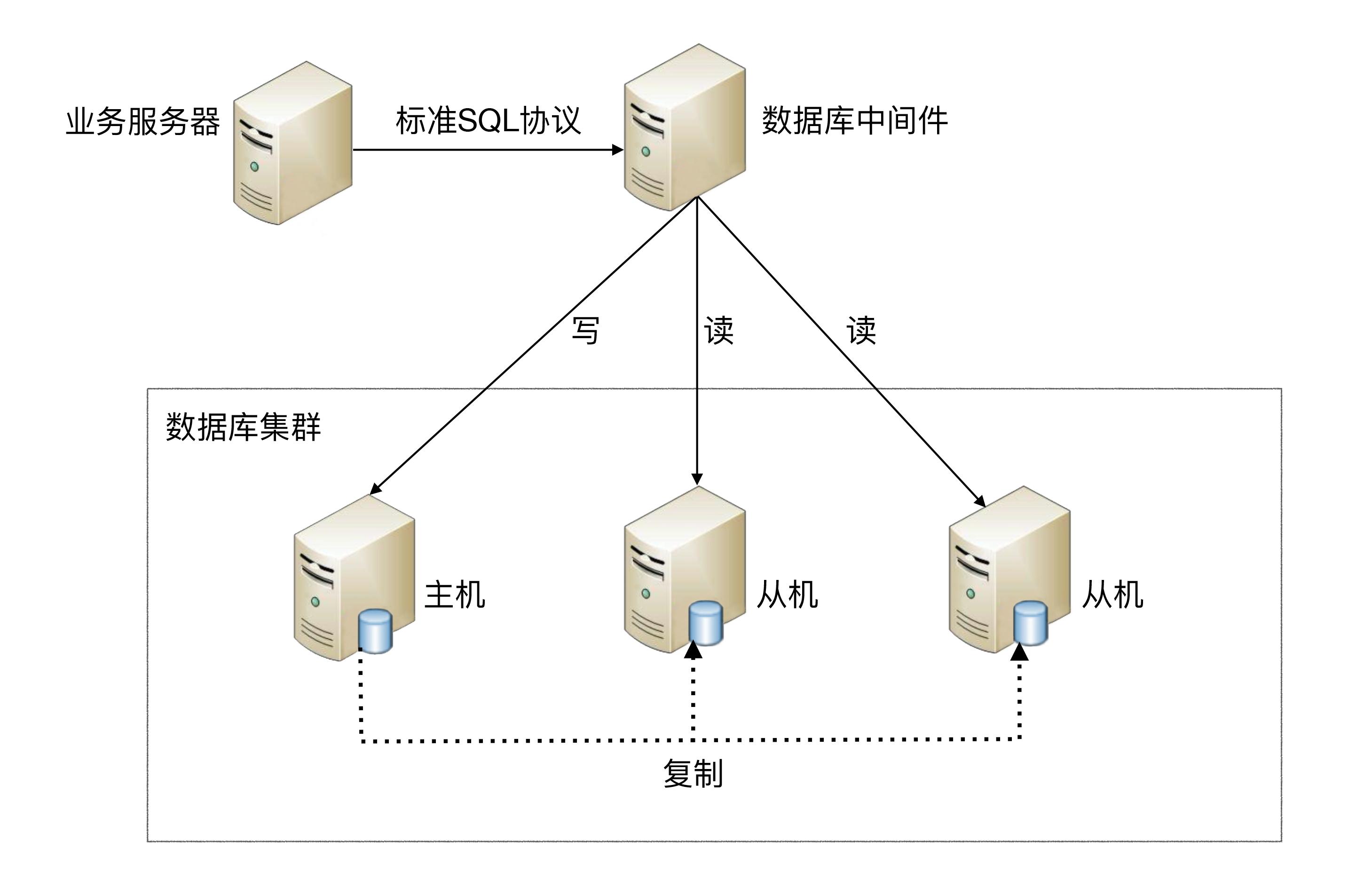
# 4.2、中间件封装
中间件封装指的是独立一套系统出来,实现读写操作分离和数据库服务器连接的管理。对于业务服务器来说,访问中间件和访问数据库没有区别,在业务服务器看来,中间件就是一个数据库服务器。
**基本架构是:**以读写分离为例
# 4.3、常用解决方案
Apache ShardingSphere(程序级别和中间件级别)
MyCat(数据库中间件)