 Numpy库
Numpy库
# Numpy库
NumPy是一个功能强大的Python库,主要用于对多维数组执行计算。NumPy这个词来源于两个单词-- Numerical和Python。NumPy提供了大量的库函数和操作,可以帮助程序员轻松地进行数值计算。在数据分析和机器学习领域被广泛使用。他有以下几个特点:
- numpy内置了并行运算功能,当系统有多个核心时,做某种计算时,numpy会自动做并行计算。
- Numpy底层使用C语言编写,内部解除了GIL(全局解释器锁),其对数组的操作速度不受Python解释器的限制,效率远高于纯Python代码。
- 有一个强大的N维数组对象Array(一种类似于列表的东西)。
- 实用的线性代数、傅里叶变换和随机数生成函数。
总而言之,他是一个非常高效的用于处理数值型运算的包。
# 安装
通过pip install numpy即可安装。
# 教程地址
- 官网:
https://docs.scipy.org/doc/numpy/user/quickstart.html。 - 中文文档:
https://www.numpy.org.cn/user_guide/quickstart_tutorial/index.html。
# Numpy数组和Python列表性能对比
比如我们想要对一个Numpy数组和Python列表中的每个素进行求平方。那么代码如下:
"""
@Author :frx
@Time :2021/11/13 15:29
@Version :1.0
"""
import numpy as np
import time
# Python列表的方式
t1 = time.time()
a = []
for x in range(100000):
a.append(x**2)
t2 = time.time()
t = t2 - t1
print(t)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
花费的时间大约是0.07180左右。而如果使用numpy的数组来做,那速度就要快很多了:
t3 = time.time()
b = np.arange(100000)**2
t4 = time.time()
print(t4-t3) #0.001
2
3
4
# NumPy数组基本用法
Numpy是Python科学计算库,用于快速处理任意维度的数组。NumPy提供一个N维数组类型ndarray,它描述了相同类型的“items”的集合。numpy.ndarray支持向量化运算。NumPy使用c语言写的,底部解除了GIL,其对数组的操作速度不在受python解释器限制。
# numpy中的数组
Numpy中的数组的使用跟Python中的列表非常类似。他们之间的区别如下:
- 一个列表中可以存储多种数据类型。比如
a = [1,'a']是允许的,而数组只能存储同种数据类型。 - 数组可以是多维的,当多维数组中所有的数据都是数值类型的时候,相当于线性代数中的矩阵,是可以进行相互间的运算的。
# 创建数组(np.ndarray对象)
Numpy经常和数组打交道,因此首先第一步是要学会创建数组。在Numpy中的数组的数据类型叫做ndarray。以下是两种创建的方式:
根据
Python中的列表生成:""" @Author :frx @Time :2021/11/13 15:39 @Version :1.0 """ import numpy as np a1=np.array([1,2,3,4]) print(a1) #[1 2 3 4] print(type(a1)) #<class 'numpy.ndarray'>1
2
3
4
5
6
7
8
9使用
np.arange生成,np.arange的用法类似于Python中的range:a2 = np.arange(2,21,2) print(a2)1
2使用
np.random生成随机数的数组:a1 = np.random.random(2,2) # 生成2行2列的随机数的数组 a2 = np.random.randint(0,10,size=(3,3)) # 元素是从0-10之间随机的3行3列的数组1
2使用函数生成特殊的数组:
""" @Author :frx @Time :2021/11/13 15:56 @Version :1.0 """ import numpy as np a1 = np.zeros((2,2)) #生成一个所有元素都是0的2行2列的数组 a2 = np.ones((3,2)) #生成一个所有元素都是1的3行2列的数组 a3 = np.full((2,2),8) #生成一个所有元素都是8的2行2列的数组 a4 = np.eye(3) #生成一个在斜方形上元素为1,其他元素都为0的3x3的矩阵 print(a1) print(a2) print(a3) print(a4)1
2
3
4
5
6
7
8
9
10
11
12
13
14
总结:
- 数组中的数据类型都是一致的,要么是整形,要么是浮点型,要么是字符串类型,不能同时出现多种数据类型。
- 创建数组的四种方式
- 使用np.array来创建
- 使用np.random模块来创建
- 使用np.arange来创建一个区间的数组
- 使用np上面的一些特殊函数来创建
# ndarray常用属性
# ndarray.dtype
因为数组中只能存储同一种数据类型,因此可以通过dtype获取数组中的元素的数据类型。以下是ndarray.dtype的常用的数据类型:
| 数据类型 | 描述 | 唯一标识符 |
|---|---|---|
| bool | 用一个字节存储的布尔类型(True或False) | 'b' |
| int8 | 一个字节大小,-128 至 127 | 'i1' |
| int16 | 整数,16 位整数(-32768 ~ 32767) | 'i2' |
| int32 | 整数,32 位整数(-2147483648 ~ 2147483647) | 'i4' |
| int64 | 整数,64 位整数(-9223372036854775808 ~ 9223372036854775807) | 'i8' |
| uint8 | 无符号整数,0 至 255 | 'u1' |
| uint16 | 无符号整数,0 至 65535 | 'u2' |
| uint32 | 无符号整数,0 至 2 ** 32 - 1 | 'u4' |
| uint64 | 无符号整数,0 至 2 ** 64 - 1 | 'u8' |
| float16 | 半精度浮点数:16位,正负号1位,指数5位,精度10位 | 'f2' |
| float32 | 单精度浮点数:32位,正负号1位,指数8位,精度23位 | 'f4' |
| float64 | 双精度浮点数:64位,正负号1位,指数11位,精度52位 | 'f8' |
| complex64 | 复数,分别用两个32位浮点数表示实部和虚部 | 'c8' |
| complex128 | 复数,分别用两个64位浮点数表示实部和虚部 | 'c16' |
| object_ | python对象 | 'O' |
| string_ | 字符串 | 'S' |
| unicode_ | unicode类型 | 'U' |
- 练习
"""
@Author :frx
@Time :2021/11/13 20:15
@Version :1.0
"""
import numpy as np
b=np.array([1,2,3,4,5],dtype=np.int8)
print(b) #[1 2 3 4 5]
print(b.dtype) #int8
c=np.array([1,2,3,4,5],dtype=np.float16)
print(c) #[1. 2. 3. 4. 5.]
print(c.dtype) #float16
class Person:
def __init__(self,name,age):
self.name=name
self.age=age
d=np.array([Person('知了',18),Person('蝈蝈',20)])
print(d) #[<__main__.Person object at 0x000002E8349081F0>
#<__main__.Person object at 0x000002E83472C280>]
print(d.dtype) #object
f=np.array(['a','b'],dtype='S')
print(f) #[b'a' b'b']
print(f.dtype) #|S1 String
e=np.array(['a','c'],dtype='U')
print(e) #['a' 'c']
print(e.dtype) #<U1 Unicode
uf=f.astype('U')
print(uf) #['a' 'b']
print(uf.dtype) #<U1
print(f.dtype) #|S1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
我们可以看到,Numpy中关于数值的类型比Python内置的多得多,这是因为Numpy为了能高效处理处理海量数据而设计的。举个例子,比如现在想要存储上百亿的数字,并且这些数字都不超过254(一个字节内),我们就可以将dtype设置为int8,这样就比默认使用int64更能节省内存空间了。类型相关的操作如下:
默认的数据类型:
import numpy as np a1 = np.array([1,2,3]) print(a1.dtype) # 如果是windows系统,默认是int32 # 如果是mac或者linux系统,则根据系统来1
2
3
4
5指定
dtype:import numpy as np a1 = np.array([1,2,3],dtype=np.int64) # 或者 a1 = np.array([1,2,3],dtype="i8") print(a1.dtype)1
2
3
4修改
dtype:import numpy as np a1 = np.array([1,2,3]) print(a1.dtype) # window系统下默认是int32 # 以下修改dtype a2 = a1.astype(np.int64) # astype不会修改数组本身,而是会将修改后的结果返回 print(a2.dtype)1
2
3
4
5
6
总结:
- 为什么Numpy的数组中有这么多的数据类型呢?
- Numpy本身基于C语言编写,C语言本身就是有很多数据类型,所以直接引用过来了。
- Numpy为了考虑到处理海量数据的性能,针对不同的数据给不同的数据类型,来节省内存空间,所以有不同的数据类型。
- Numpy的数组的元素有哪些数据类型? 看上图
- 使用ndarray.astype可以修改数组元素的数据类型。
# ndarray.size
获取数组中总的元素的个数。比如有个二维数组:
import numpy as np
a1 = np.array([[1,2,3],[4,5,6]])
print(a1.size) #打印的是6,因为总共有6个元素
2
3
# ndarray.ndim
数组的维数。比如:
a1 = np.array([1,2,3])
print(a1.ndim) # 维度为1
a2 = np.array([[1,2,3],[4,5,6]])
print(a2.ndim) # 维度为2
a3 = np.array([[[1,2,3],[4,5,6]],[[7,8,9],[10,11,12]]])
print(a3.ndim) # 维度为3
2
3
4
5
6
# ndarray.shape
数组的维度的元组。比如以下代码:
a1 = np.array([1,2,3])
print(a1.shape) # 输出(3,),意思是一维数组,有3个数据
a2 = np.array([[1,2,3],[4,5,6]])
print(a2.shape) # 输出(2,3),意思是二位数组,2行3列
a3 = np.array([
[
[1,2,3],
[4,5,6]
],
[
[7,8,9],
[10,11,12]
]
])
print(a3.shape) # 输出(2,2,3),意思是三维数组,总共有2个元素,每个元素是2行3列的
a44 = np.array([1,2,3],[4,5])
print(a4.shape) # 输出(2,),意思是a4是一个一维数组,总共有2列
print(a4) # 输出[list([1, 2, 3]) list([4, 5])],其中最外面层是数组,里面是Python列表
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
另外,我们还可以通过ndarray.reshape来重新修改数组的维数。示例代码如下:
a1 = np.arange(12) #生成一个有12个数据的一维数组
print(a1)
a2 = a1.reshape((3,4)) #变成一个2维数组,是3行4列的
print(a2)
a3 = a1.reshape((2,3,2)) #变成一个3维数组,总共有2块,每一块是2行2列的
print(a3)
a4 = a2.reshape((12,)) # 将a2的二维数组重新变成一个12列的1维数组
print(a4)
a5 = a2.flatten() # 不管a2是几维数组,都将他变成一个一维数组
print(a5)
2
3
4
5
6
7
8
9
10
11
12
13
14
- 练习
"""
@Author :frx
@Time :2021/11/14 16:25
@Version :1.0
"""
import numpy as np
a1=np.array([1,2,3])
print(a1.ndim) #1
a2=np.array([[1,2,3],[4,5,6]])
print(a2.ndim) #2
a3=np.array([
[
[1,2,3],
[4,5,6] ],
[
[7,8,9],
[10,11,12]
]
])
print(a3.ndim) #3
print(a1.shape) #(3,)
print(a2.shape) #(2, 3)
print(a3.shape) #(2,2,3) 几维几行几列
print(a3.reshape(2,6)) #保证元素个数不变
# print(a3.reshape(1,12)) #两维 一行
print(a3.reshape(12,)) #转换为一维数组
print(a3.flatten()) #调用函数生成一维数组
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
注意,reshape并不会修改原来数组本身,而是会将修改后的结果返回。如果想要直接修改数组本身,那么可以使用resize来替代reshape。
# ndarray.itemsize
数组中每个元素占的大小,单位是字节。比如以下代码:
a1 = np.array([1,2,3],dtype=np.int32)
print(a1.itemsize) # 打印4,因为每个字节是8位,32位/8=4个字节
2
总结
- 数组一般达到3维就已经很复杂了,不太方便计算,所以我们一般都会把3维以上的数组转换成2维数组来计算
- 通过ndarray.ndim可以看到数组的维度
- 通过ndarray.shape可以看到数组的形状(几行几列),shape是一个元组,里面有几个元素代表是几维数组
- 通过ndarray.reshape可以修改数组的形状,条件只有一个,就是修改后的形状的元素个数必须和原来的个数一致。比如原来是(2,6),那么修改完成后可以变成(3,4),但是不能变成(1,4)。reshape不会修改原来数组的形状,他只会将修改后的结果返回。
- 通过ndarray.size可以看到数组总共有多少个元素。
- 通过ndarray.itemsize可以看到数组中每个元素所占内存的大小,单位是字节。(一个字节=8位)
# Numpy数组操作
# 索引和切片
获取某行的数据:
# 1. 如果是一维数组 a1 = np.arange(0,29) print(a1[1]) #获取下标为1的元素 a1 = np.arange(0,24).reshape((4,6)) print(a1[1]) #获取下标为1的行的数据1
2
3
4
5
6连续获取某几行的数据:
# 1. 获取连续的几行的数据 a1 = np.arange(0,24).reshape((4,6)) print(a1[0:2]) #获取0行到1行的数据 # 2. 获取不连续的几行的数据 print(a1[[0,2,3]]) # 3. 也可以使用负数进行索引 print(a1[[-1,-2]])1
2
3
4
5
6
7
8
9获取某行某列的数据:
a1 = np.arange(0,24).reshape((4,6)) print(a1[1,1]) #获取1行1列的数据 print(a1[0:2,0:2]) #获取0-1行的0-1列的数据 print(a1[[1,2],[2,3]]) #获取(1,2)和(2,3)的两个数据,这也叫花式索引1
2
3
4
5获取某列的数据:
a1 = np.arange(0,24).reshape((4,6)) print(a1[:,1]) #获取第1列的数据1
2
- 练习
"""
@Author :frx
@Time :2021/11/16 16:00
@Version :1.0
"""
#一维数组的索引和切片
import numpy as np
a1=np.arange(10)
#1.1进行索引操作
print(a1[4]) #4
#1.2进行切片操作
print(a1[4:6]) #[4 5]
#1.3使用步长
print(a1[::2]) #[0 2 4 6 8]
#1.4使用负数来作为索引
print(a1[-1]) #9
#2.多维数组
#也是通过中括号来索引和切片.在中括号中,使用逗号进行分割,逗号前面的是行,
#逗号后面的是列,如果多维数组中只有一个值,那么这个值就是行
a2=np.random.randint(0,10,size=(4,6))
print(a2)
print(a2[0])
print(a2[1:3]) #获取2到3行数组
print(a2[[1,2]])
print(a2[1,2],[4,5]) #获取第2行第5列 和第3行第6列
print(a2[1:3,4:6]) #获取第1 2 行的 4 5 列
print(a2[:,1]) #获取第一列的数据
print(a2[:,[1,3]]) #获取1 3列的数据
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
总结:
- 如果数组是一维的,那么索引和切片就是跟python的列表是一样的。
- 如果是多维的(这里以二维为例),那么在中括号中,给两个值,两个值是通过逗号分割的,逗号前面是行,逗号后面是列。如果中括号中只有一个值,那么就是代表的是行。
- 如果是多维数组(这里以二维为例),那么行的部分和列的部分,都是遵循一维度数组的方式,可以使用整形,切片,还可以使用中括号的形式来代表不连续的。比如a[[1,2],[3,4]],那么返回的是(1,3),(2,4)的两个值。
# 布尔索引
布尔运算也是矢量的,比如以下代码:
a1 = np.arange(0,24).reshape((4,6))
print(a1<10) #会返回一个新的数组,这个数组中的值全部都是bool类型
> [[ True True True True True True]
[ True True True True False False]
[False False False False False False]
[False False False False False False]]
2
3
4
5
6
这样看上去没有什么用,假如我现在要实现一个需求,要将a1数组中所有小于10的数据全部都提取出来。那么可以使用以下方式实现:
a1 = np.arange(0,24).reshape((4,6))
a2 = a1 < 10
print(a1[a2]) #这样就会在a1中把a2中为True的元素对应的位置的值提取出来
2
3
其中布尔运算可以有!=、==、>、<、>=、<=以及&(与)和|(或)。示例代码如下:
a1 = np.arange(0,24).reshape((4,6))
a2 = a1[(a1 < 5) | (a1 > 10)]
print(a2)
2
3
- 练习
"""
@Author :frx
@Time :2021/11/19 14:26
@Version :1.0
"""
import numpy as np
a2=np.arange(24).reshape((4,6))
print(a2)
print(a2<10)
print(a2[a2<10]) #获取元素小于10的数组
print(a2[(a2<5)|(a2>10)])
2
3
4
5
6
7
8
9
10
11
总结:
布尔索引是通过相同数组上的True还是False来进行提取的。提取条件可以有多个,那么如果有多个,可以使用&来代替且,用|来代替或,如果有多个条件,那么每个条件要使用圆括号括起来。
# 值的替换
利用索引,也可以做一些值的替换。把满足条件的位置的值替换成其他的值。比如以下代码:
a1 = np.arange(0,24).reshape((4,6))
a1[3] = 0 #将第三行的所有值都替换成0
print(a1)
2
3
也可以使用条件索引来实现:
a1 = np.arange(0,24).reshape((4,6))
a1[a1 < 5] = 0 #将小于5的所有值全部都替换成0
print(a1)
2
3
还可以使用函数来实现:
# where函数:
a1 = np.arange(0,24).reshape((4,6))
a2 = np.where(a1 < 10,1,0) #把a1中所有小于10的数全部变成1,其余的变成0
print(a2)
2
3
4
- 练习
"""
@Author :frx
@Time :2021/11/19 14:46
@Version :1.0
"""
import numpy as np
a3=np.random.randint(0,10,size=(3,5))
print(a3)
a3[1]=0 #把a3第二行变为0
a3[2]=np.array([1,2,3,4,5]) #把a3的第三行换成1,2,3,4,5
print(a3)
a3[a3<3]=1 #把元素小于3的全部替换为1
print(a3)
a3=np.where(a3<5,1,0)# 把a3小于10的 全部替换为1 其余为0
print(a3)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
总结:
- 可以使用索引或者切片来替换。
- 使用条件索引来替换。
- 使用where函数来实现。
# 数组广播机制
# 数组与数的计算
在Python列表中,想要对列表中所有的元素都加一个数,要么采用map函数,要么循环整个列表进行操作。但是NumPy中的数组可以直接在数组上进行操作。示例代码如下:
import numpy as np
a1 = np.random.random((3,4))
print(a1)
# 如果想要在a1数组上所有元素都乘以10,那么可以通过以下来实现
a2 = a1*10
print(a2)
# 也可以使用round让所有的元素只保留2位小数
a3 = a2.round(2)
2
3
4
5
6
7
8
以上例子是相乘,其实相加、相减、相除也都是类似的。
# 数组与数组的计算
结构相同的数组之间的运算:
a1 = np.arange(0,24).reshape((3,8)) a2 = np.random.randint(1,10,size=(3,8)) a3 = a1 + a2 #相减/相除/相乘都是可以的 print(a1) print(a2) print(a3)1
2
3
4
5
6与行数相同并且只有1列的数组之间的运算:
a1 = np.random.randint(10,20,size=(3,8)) #3行8列 a2 = np.random.randint(1,10,size=(3,1)) #3行1列 a3 = a1 - a2 #行数相同,且a2只有1列,能互相运算 print(a3)1
2
3
4与列数相同并且只有1行的数组之间的运算:
a1 = np.random.randint(10,20,size=(3,8)) #3行8列 a2 = np.random.randint(1,10,size=(1,8)) a3 = a1 - a2 print(a3)1
2
3
4
# 广播原则
如果两个数组的后缘维度(trailing dimension,即从末尾开始算起的维度)的轴长度相符或其中一方的长度为1,则认为他们是广播兼容的。广播会在缺失和(或)长度为1的维度上进行。。看以下案例分析:
shape为(3,8,2)的数组能和(8,3)的数组进行运算吗?
分析:不能,因为按照广播原则,从后面往前面数,(3,8,2)和(8,3)中的2和3不相等,所以不能进行运算。shape为(3,8,2)的数组能和(8,1)的数组进行运算吗?
分析:能,因为按照广播原则,从后面往前面数,(3,8,2)和(8,1)中的2和1虽然不相等,但是因为有一方的长度为1,所以能参与运算。shape为(3,1,8)的数组能和(8,1)的数组进行运算吗?
分析:能,因为按照广播原则,从后面往前面数,(3,1,4)和(8,1)中的4和1虽然不相等且1和8不相等,但是因为这两项中有一方的长度为1,所以能参与运算。
- 练习
"""
@Author :frx
@Time :2021/11/19 15:31
@Version :1.0
"""
import numpy as np
a1=np.random.randint(0,5,size=(3,5))
print(a1)
print(a1*2)
a2=np.random.randint(0,5,size=(3,5))
print(a2)
print(a1+a2)
a3=np.random.randint(0,5,size=(3,1))
print(a3)
print(a1+a3) #a1的每一列 都加a3
a4=np.random.randint(0,5,size=(1,5))
print(a4)
print(a1+a4) #a1的 每一行 都加a4
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
总结`:
- 数组和数字直接进行运算是没有问题的。
- 两个shape相同的数组是可以进行运算的。
- 如果两个shape不同的数组,想要进行运算,那么需要看他们是否满足广播原则。
- 广播原则:如果两个数组的后缘维度(trailing dimension,即从末尾开始算起的维度)的轴长度相符或其中一方的长度为1,则认为他们是广播兼容的。广播会在缺失和(或)长度为1的维度上进行。
# 数组形状的操作
可以通过一些函数,非常方便的操作数组的形状。
# reshape和resize方法
两个方法都是用来修改数组形状的,但是有一些不同。
reshape是将数组转换成指定的形状,然后返回转换后的结果,对于原数组的形状是不会发生改变的。调用方式:a1 = np.random.randint(0,10,size=(3,4)) a2 = a1.reshape((2,6)) #将修改后的结果返回,不会影响原数组本身1
2resize是将数组转换成指定的形状,会直接修改数组本身。并不会返回任何值。调用方式:a1 = np.random.randint(0,10,size=(3,4)) a1.resize((2,6)) #a1本身发生了改变1
2
# flatten和ravel方法
两个方法都是将多维数组转换为一维数组,但是有以下不同:
flatten是将数组转换为一维数组后,然后将这个拷贝返回回去,所以后续对这个返回值进行修改不会影响之前的数组。ravel是将数组转换为一维数组后,将这个视图(可以理解为引用)返回回去,所以后续对这个返回值进行修改会影响之前的数组。
比如以下代码:
x = np.array([[1, 2], [3, 4]])
x.flatten()[1] = 100 #此时的x[0]的位置元素还是1
x.ravel()[1] = 100 #此时x[0]的位置元素是100
2
3
- 练习
"""
@Author :frx
@Time :2021/11/19 18:44
@Version :1.0
"""
import numpy as np
a1=np.random.randint(0,10,size=(3,4))
print(a1)
print(a1.reshape(2,6)) #本身没有改变 转换为2行6列
print(a1.resize(4,3)) #没有返回值
print(a1)
#flaten和ravel函数
a2=np.random.randint(0,10,size=(3,4))
print(a2)
print(a2.flatten()) #[8 9 7 8 4 7 9 9 1 5 9 0]
a3=a2.flatten()
a3[0]=100
print(a2) #返回不会修改原来的数组
print(a2.ravel()) #[9 1 8 7 2 2 5 4 4 9 6 9]
a3=a2.ravel()#返回的引用
a3[0]=100
print(a2) #原来的数组发生了改变
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
总结:
- reshape和resize都是重新定义形状的。但是reshape不会修改数组本身,而是将修改后的结果返回回去,而resize是直接修改本身的。
- flatten和ravel都是用来将数组变成一维数组的,并且他们都不会对原数组造成修改,但是flatten返回的是一个拷贝,所以对flatten的返回值的修改不会影响到原来数组,而ravel返回的是一个view,那么返回值的修改会影响到原来数组的值。
# 不同数组的组合
如果有多个数组想要组合在一起,也可以通过其中的一些函数来实现。
vstack:将数组按垂直方向进行叠加。数组的列数必须相同才能叠加。示例代码如下:a1 = np.random.randint(0,10,size=(3,5)) a2 = np.random.randint(0,10,size=(1,5)) a3 = np.vstack([a1,a2])1
2
3hstack:将数组按水平方向进行叠加。数组的行必须相同才能叠加。示例代码如下:a1 = np.random.randint(0,10,size=(3,2)) a2 = np.random.randint(0,10,size=(3,1)) a3 = np.hstack([a1,a2])1
2
3concatenate([],axis):将两个数组进行叠加,但是具体是按水平方向还是按垂直方向。则要看axis的参数,如果axis=0,那么代表的是往垂直方向(行)叠加,如果axis=1,那么代表的是往水平方向(列)上叠加,如果axis=None,那么会将两个数组组合成一个一维数组。需要注意的是,如果往水平方向上叠加,那么行必须相同,如果是往垂直方向叠加,那么列必须相同。示例代码如下:a = np.array([[1, 2], [3, 4]]) b = np.array([[5, 6]]) np.concatenate((a, b), axis=0) # 结果: array([[1, 2], [3, 4], [5, 6]]) np.concatenate((a, b.T), axis=1) # 结果: array([[1, 2, 5], [3, 4, 6]]) np.concatenate((a, b), axis=None) # 结果: array([1, 2, 3, 4, 5, 6])1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
- 练习
"""
@Author :frx
@Time :2021/11/19 21:00
@Version :1.0
"""
import numpy as np
vstake1=np.random.randint(0,10,size=(3,4))
print(vstake1)
vstake2=np.random.randint(0,10,size=(2,4))
print(vstake2)
# vstake3=np.vstack([vstake1,vstake2]) #按垂直方向叠加,数组的列必须相同
vstake3=np.concatenate([vstake1,vstake2],axis=0) #0水平方向
print(vstake3)
hstack1=np.random.randint(0,10,size=(3,1))
print(hstack1)
hstack2=np.random.randint(0,10,size=(3,4))
print(hstack2)
# hstack3=np.hstack([hstack1,hstack2]) #按水平方向叠加,数组的行必须相同
hstack3=np.concatenate([hstack1,hstack2],axis=1) #1 垂直方向
print(hstack3)
h4=np.concatenate([hstack1,hstack2],axis=None) #通过叠加 变为一维数组
print(h4)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
总结:
- hstack代表在水平方向叠加,如果想要叠加成功,那么他们的行必须一致。
- vstack代表在垂直方向叠加,如果想要叠加成功,那么他们的列必须一致。
- concatenate可以手动的指定axis参数具体在哪个方向叠加,如果axis=0,代表在水平方向叠加,如果axis=1,代表在垂直方向叠加,如果axis=None,那么会先进行叠加,再转换为1维数组。
# 数组的切割
通过hsplit和vsplit以及array_split可以将一个数组进行切割。
hsplit:按照水平方向进行切割。用于指定分割成几列,可以使用数字来代表分成几部分,也可以使用数组来代表分割的地方。示例代码如下:a1 = np.arange(16.0).reshape(4, 4) np.hsplit(a1,2) #分割成两部分 >>> array([[ 0., 1.], [ 4., 5.], [ 8., 9.], [12., 13.]]), array([[ 2., 3.], [ 6., 7.], [10., 11.], [14., 15.]])] np.hsplit(a1,[1,2]) #代表在下标为1的地方切一刀,下标为2的地方切一刀,分成三部分 >>> [array([[ 0.], [ 4.], [ 8.], [12.]]), array([[ 1.], [ 5.], [ 9.], [13.]]), array([[ 2., 3.], [ 6., 7.], [10., 11.], [14., 15.]])]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21vsplit:按照垂直方向进行切割。用于指定分割成几行,可以使用数字来代表分成几部分,也可以使用数组来代表分割的地方。示例代码如下:np.vsplit(x,2) #代表按照行总共分成2个数组 >>> [array([[0., 1., 2., 3.], [4., 5., 6., 7.]]), array([[ 8., 9., 10., 11.], [12., 13., 14., 15.]])] np.vsplit(x,(1,2)) #代表按照行进行划分,在下标为1的地方和下标为2的地方分割 >>> [array([[0., 1., 2., 3.]]), array([[4., 5., 6., 7.]]), array([[ 8., 9., 10., 11.], [12., 13., 14., 15.]])]1
2
3
4
5
6
7
8
9
10split/array_split(array,indicate_or_seciont,axis):用于指定切割方式,在切割的时候需要指定是按照行还是按照列,axis=1代表按照列,axis=0代表按照行。示例代码如下:np.array_split(x,2,axis=0) #按照垂直方向切割成2部分 >>> [array([[0., 1., 2., 3.], [4., 5., 6., 7.]]), array([[ 8., 9., 10., 11.], [12., 13., 14., 15.]])]1
2
3
4
- 练习
"""
@Author :frx
@Time :2021/11/19 21:41
@Version :1.0
"""
import numpy as np
hs1=np.random.randint(0,10,size=(3,4))
print(hs1)
hs2=np.hsplit(hs1,2)
print(hs2)
hs3=np.hsplit(hs1,(1,2)) #在下标为1和2的列前面切一刀
print(hs3)
vs1=np.random.randint(0,10,size=(4,5))
print(vs1)
vs2=np.vsplit(vs1,4) #水平分割
print(vs2)
vs3=np.vsplit(vs1,(1,3))
print(vs3)
hs4=np.split(hs1,4,axis=1) #垂直切割
print(hs4)
vs4=np.split(vs1,4,axis=0) #水平切割
print(vs4)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
总结:
- hsplit代表在水平方向切割,按列进行切割的。它的切割方式有两种,第一种就是直接指定平均切割成多少列,第二种就是指定切割的下标值。
- vsplit代表在垂直方向切割,按行进行切割的。它的切割方式跟hspilt是一样的。
- split/array_split是手动的指定axis参数,axis=0,代表按行切割,axis=1,代表按列进行切割。
# 数组(矩阵)转置和轴对换
numpy中的数组其实就是线性代数中的矩阵。矩阵是可以进行转置的。ndarray有一个T属性,可以返回这个数组的转置的结果。示例代码如下:
a1 = np.arange(0,24).reshape((4,6))
a2 = a1.T
print(a2)
2
3
另外还有一个方法叫做transpose,这个方法返回的是一个View,也即修改返回值,会影响到原来数组。示例代码如下:
a1 = np.arange(0,24).reshape((4,6))
a2 = a1.transpose()
2
为什么要进行矩阵转置呢,有时候在做一些计算的时候需要用到。比如做矩阵的内积的时候。就必须将矩阵进行转置后再乘以之前的矩阵:
a1 = np.arange(0,24).reshape((4,6))
a2 = a1.T
print(a1.dot(a2))
2
3
# 深拷贝和浅拷贝
在操作数组的时候,它们的数据有时候拷贝进一个新的数组,有时候又不是。这经常是初学者感到困惑。下面有三种情况:
# 不拷贝
如果只是简单的赋值,那么不会进行拷贝。示例代码如下:
a = np.arange(12)
b = a #这种情况不会进行拷贝
print(b is a) #返回True,说明b和a是相同的
2
3
# View或者浅拷贝
有些情况,会进行变量的拷贝,但是他们所指向的内存空间都是一样的,那么这种情况叫做浅拷贝,或者叫做View(视图)。比如以下代码:
a = np.arange(12)
c = a.view()
print(c is a) #返回False,说明c和a是两个不同的变量
c[0] = 100
print(a[0]) #打印100,说明对c上的改变,会影响a上面的值,说明他们指向的内存空间还是一样的,这种叫做浅拷贝,或者说是view
2
3
4
5
# 深拷贝
将之前数据完完整整的拷贝一份放到另外一块内存空间中,这样就是两个完全不同的值了。示例代码如下:
a = np.arange(12)
d = a.copy()
print(d is a) #返回False,说明d和a是两个不同的变量
d[0] = 100
print(a[0]) #打印0,说明d和a指向的内存空间完全不同了。
2
3
4
5
# 例子
像之前讲到的flatten和ravel就是这种情况,ravel返回的就是View,而flatten返回的就是深拷贝。
总结:
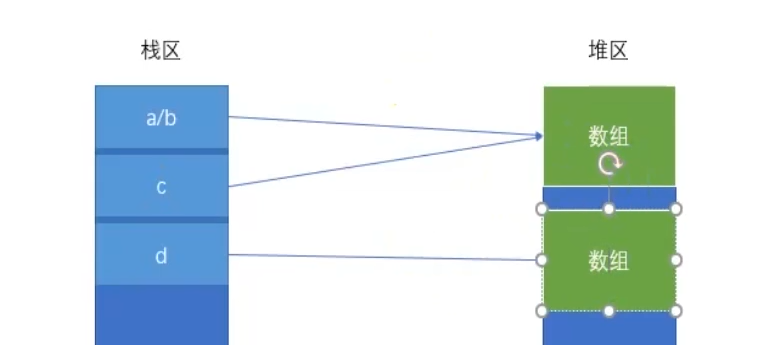
在数组操作中分成三种拷贝:
- 不拷贝:直接赋值,那么栈区没有拷贝,只是用同一个栈区定义了不同的名称。
- 浅拷贝:只拷贝栈区,栈区指定的堆区并没有拷贝。
- 深拷贝:栈区和堆区都拷贝了。
# 文件操作
# 操作CSV文件
# 文件保存
有时候我们有了一个数组,需要保存到文件中,那么可以使用np.savetxt来实现。相关的函数描述如下:
np.savetxt(frame, array, fmt='%.18e', delimiter=None)
* frame : 文件、字符串或产生器,可以是.gz或.bz2的压缩文件
* array : 存入文件的数组
* comments='#':默认为#
* header='英语,数学'#头部信息 标题
* fmt : 写入文件的格式,例如:%d %.2f %.18e
* delimiter : 分割字符串,默认是任何空格
2
3
4
5
6
7
以下是使用的例子:
a = np.arange(100).reshape(5,20)
np.savetxt("a.csv",a,fmt="%d",delimiter=",")
2
# 读取文件
有时候我们的数据是需要从文件中读取出来的,那么可以使用np.loadtxt来实现。相关的函数描述如下:
np.loadtxt(frame, dtype=np.float, delimiter=None, unpack=False)
* frame:文件、字符串或产生器,可以是.gz或.bz2的压缩文件。
* dtype:数据类型,可选。
* delimiter:分割字符串,默认是任何空格。
* skiprows:跳过前面x行。
* usecols:读取指定的列,用元组组合。
* unpack:如果True,读取出来的数组是转置后的。
2
3
4
5
6
7
- 练习
#encoding=gbk
"""
@Author :frx
@Time :2021/11/24 12:58
@Version :1.0
"""
import numpy as np
scores=np.random.randint(0,100,size=(20,2))
print(scores)
np.savetxt("score.csv",scores,delimiter=",",header='英语,数学',comments='',fmt='%d')
b=np.loadtxt("score.csv",dtype=np.int,delimiter=',',skiprows=1) #跳过第一行,
print(b)
2
3
4
5
6
7
8
9
10
11
12
13
# np独有的存储解决方案
numpy中还有一种独有的存储解决方案。文件名是以.npy或者npz结尾的。以下是存储和加载的函数。
- 存储:
np.save(fname,array)或np.savez(fname,array)。其中,前者函数的扩展名是.npy,后者的扩展名是.npz,后者是经过压缩的。 - 加载:
np.load(fname)。
- 练习
"""
@Author :frx
@Time :2021/11/24 23:18
@Version :1.0
"""
import numpy as np
c=np.random.randint(0,10,size=(2,3))
np.save('c',c)
c1=np.load('c.npy') #读取
print(c1)
d=np.random.randint(0,10,size=(2,3,4))
# np.savetxt('d.csv',d) # 只能保存一维或二维数组 报错
np.save('d',d)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
总结:
- np.savetxt和np.loadtxt一般用来操作csv文件,他可以设置header,但是不能存储3维以上的数组。
- np.save和np.load一般用来存储非文本类型的文件,他不可以设置header,但是可以存储3维以上的数组。
- 如果想专门的操作csv文件,其实还有另一个模块叫做csv,这个模块是Python内置的,不需要安装。
# CSV文件操作
# 读取csv文件
import csv
with open('stock.csv','r') as fp:
reader = csv.reader(fp)
titles = next(reader)
for x in reader:
print(x)
2
3
4
5
6
7
这样操作,以后获取数据的时候,就要通过下表来获取数据。如果想要在获取数据的时候通过标题来获取。那么可以使用DictReader。示例代码如下:
import csv
with open('stock.csv','r') as fp:
reader = csv.DictReader(fp)
for x in reader:
print(x['turnoverVol'])
2
3
4
5
6
- 练习
"""
@Author :frx
@Time :2021/11/25 9:31
@Version :1.0
"""
import csv
with open('stock.csv','r') as fp:
reader=csv.reader(fp) #reader是一个迭代器
next(reader) #标题数据就没有了
for x in reader:
name=x[3]
volumn=x[-1]
print({'name':name,'volumn':volumn}) #只获取名字和成交量
def read_csv_demo2():
with open('stock.csv','r') as fp:
#使用DictReader创建的reader对象
#不会包含标题那行的数据
#reader是一个迭代器,遍历这个迭代器,返回来的是一个字典
reader=csv.DictReader(fp)
for x in reader:
values={'name':x['secShortName'],'volumn':x['turnoverVol']}
print(values)
if __name__=='__main__':
read_csv_demo2()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 写入数据到csv文件
写入数据到csv文件,需要创建一个writer对象,主要用到两个方法。一个是writerow,这个是写入一行。一个是writerows,这个是写入多行。示例代码如下:
import csv
headers = ['name','age','classroom']
values = [
('zhiliao',18,'111'),
('wena',20,'222'),
('bbc',21,'111')
]
with open('test.csv','w',newline='') as fp:
writer = csv.writer(fp)
writer.writerow(headers)
writer.writerows(values)
2
3
4
5
6
7
8
9
10
11
12
也可以使用字典的方式把数据写入进去。这时候就需要使用DictWriter了。示例代码如下:
import csv
headers = ['name','age','classroom']
values = [
{"name":'wenn',"age":20,"classroom":'222'},
{"name":'abc',"age":30,"classroom":'333'}
]
with open('test.csv','w',newline='') as fp:
writer = csv.DictWriter(fp,headers)
writer.writerow({'name':'zhiliao',"age":18,"classroom":'111'})
writer.writerows(values)
2
3
4
5
6
7
8
9
10
11
- 练习
"""
@Author :frx
@Time :2021/11/25 9:48
@Version :1.0
"""
import csv
def write_csv_demo1():
headers={'username','age','height'}
values=[
('张三',18,180),
('李四',18,190),
('王五',19,160)
]
with open('classroom.csv','w',encoding='utf-8',newline='') as fp:
writer=csv.writer(fp)
writer.writerow(headers)
writer.writerows(values)
def write_csv_demo2():
headers={'username','age','height'}
values=[
{'username':'张三','age':18,'height':180},
{'username':'李四','age':19,'height':160},
{'username':'张三','age':20,'height':190},
]
with open('classroom1.csv','w',encoding='utf-8',newline='') as fp:
writer=csv.DictWriter(fp,headers)
#写入表头数据的时候需要调用writeheader方法
writer.writeheader()
writer.writerows(values)
if __name__=='__main__':
write_csv_demo2()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# NAN和INF值处理
首先我们要知道这两个英文单词代表的什么意思:
NAN:Not A number,不是一个数字的意思,但是他是属于浮点类型的,所以想要进行数据操作的时候需要注意他的类型。INF:Infinity,代表的是无穷大的意思,也是属于浮点类型。np.inf表示正无穷大,-np.inf表示负无穷大,一般在出现除数为0的时候为无穷大。比如2/0。
# NAN一些特点
- NAN和NAN不相等。比如
np.NAN != np.NAN这个条件是成立的。 - NAN和任何值做运算,结果都是NAN。
有些时候,特别是从文件中读取数据的时候,经常会出现一些缺失值。缺失值的出现会影响数据的处理。因此我们在做数据分析之前,先要对缺失值进行一些处理。处理的方式有多种,需要根据实际情况来做。一般有两种处理方式:删除缺失值,用其他值进行填充。
# 删除缺失值
有时候,我们想要将数组中的NAN删掉,那么我们可以换一种思路,就是只提取不为NAN的值。示例代码如下:
# 1. 删除所有NAN的值,因为删除了值后数组将不知道该怎么变化,所以会被变成一维数组
data = np.random.randint(0,10,size=(3,5)).astype(np.float)
data[0,1] = np.nan
data = data[~np.isnan(data)] # 此时的data会没有nan,并且变成一个1维数组
# 2. 删除NAN所在的行
data = np.random.randint(0,10,size=(3,5)).astype(np.float)
# 将第(0,1)和(1,2)两个值设置为NAN
data[[0,1],[1,2]] = np.NAN
# 获取哪些行有NAN
lines = np.where(np.isnan(data))[0]
# 使用delete方法删除指定的行,axis=0表示删除行,lines表示删除的行号
data1 = np.delete(data,lines,axis=0)
2
3
4
5
6
7
8
9
10
11
12
13
- 练习
"""
@Author :frx
@Time :2021/11/25 10:10
@Version :1.0
"""
import numpy as np
data=np.random.randint(0,10,size=(3,5))
print(data)
data=data.astype(np.float)
data[0,1]=np.NAN
print(data)
# print(data/0)
print(np.NAN==np.NAN) #False #Nan和任何值做运算 等于Nan
print(data[~np.isnan(data)]) #提取非Nan的值
data[1,2]=np.NAN
lines=np.where(np.isnan(data))[0]
data=np.delete(data,lines,axis=0) #删除行
print(data)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# 用其他值进行替代
有些时候我们不想直接删掉,比如有一个成绩表,分别是数学和英语,但是因为某个人在某个科目上没有成绩,那么此时就会出现NAN的情况,这时候就不能直接删掉了,就可以使用某些值进行替代。假如有以下表格:
| 数学 | 英语 |
|---|---|
| 59 | 89 |
| 90 | 32 |
| 78 | 45 |
| 34 | NAN |
| NAN | 56 |
| 23 | 56 |
如果想要求每门成绩的总分,以及每门成绩的平均分,那么就可以采用某些值替代。比如求总分,那么就可以把NAN替换成0,如果想要求平均分,那么就可以把NAN替换成其他值的平均值。示例代码如下:
scores = np.loadtxt("nan_scores.csv",skiprows=1,delimiter=",",encoding="utf-8",dtype=np.str)
scores[scores == ""] = np.NAN
scores = scores.astype(np.float)
# 1. 求出学生成绩的总分
scores1 = scores.copy()
socres1.sum(axis=1)
# 2. 求出每门成绩的平均分
scores2 = scores.copy()
for x in range(scores2.shape[1]):
score = scores2[:,x]
non_nan_score = score[score == score]
score[score != score] = non_nan_score.mean()
print(scores2.mean(axis=0))
2
3
4
5
6
7
8
9
10
11
12
13
14
- 练习
"""
@Author :frx
@Time :2021/11/25 11:01
@Version :1.0
"""
import numpy as np
scores=np.loadtxt('nan_scores.csv',delimiter=',',skiprows=1,encoding='utf-8',dtype=np.str)
scores[scores=='']=np.NAN
print(scores)
scores1=scores.astype(np.float)
scores1[np.isnan(scores1)]=0
#除了delete用axis=0来表示行以外,其他的大部分函数都是axis=1来表示行
scores1_sum=scores1.sum(axis=1)
print(scores1_sum)
scores2=scores.astype(np.float)
for x in range(scores2.shape[1]):
col=scores2[:,x]
non_nan_col=col[~np.isnan(col)]
mean=non_nan_col.mean()
col[np.isnan(col)]=mean
print(scores2)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
总结:
- NAN:Not A Number的简写,不是一个数字,但是他是属于浮点型。
- INF:无穷大,在除数为0的情况下会出现INF。
- NAN和所有的值进行计算结果都是等于NAN。
- NAN!=NAN
- 可以通过np.isnan来判断某个值是不是NAN。
- 处理值的时候,可以通过删除NAN的形式进行处理,也可以通过值的替换处理。
- np.delete比较特殊,他通过axis=0来代表行,而其他大部分函数是通过axis=1来代表行。
# np.random模块
np.random为我们提供了许多获取随机数的函数。这里统一来学习一下。
# np.random.seed
用于指定随机数生成时所用算法开始的整数值,如果使用相同的seed()值,则每次生成的随即数都相同,如果不设置这个值,则系统根据时间来自己选择这个值,此时每次生成的随机数因时间差异而不同。一般没有特殊要求不用设置。以下代码:
np.random.seed(1)
print(np.random.rand()) # 打印0.417022004702574
print(np.random.rand()) # 打印其他的值,因为随机数种子只对下一次随机数的产生会有影响。
2
3
# np.random.rand
生成一个值为[0,1)之间的数组,形状由参数指定,如果没有参数,那么将返回一个随机值。示例代码如下:
data1 = np.random.rand(2,3,4) # 生成2块3行4列的数组,值从0-1之间
data2 = np.random.rand() #生成一个0-1之间的随机数
2
# np.random.randn
生成均值(μ)为0,标准差(σ)为1的标准正态分布的值。示例代码如下:
data = np.random.randn(2,3) #生成一个2行3列的数组,数组中的值都满足标准正太分布
# np.random.randint
生成指定范围内的随机数,并且可以通过size参数指定维度。示例代码如下:
data1 = np.random.randint(10,size=(3,5)) #生成值在0-10之间,3行5列的数组
data2 = np.random.randint(1,20,size=(3,6)) #生成值在1-20之间,3行6列的数组
2
# np.random.choice
从一个列表或者数组中,随机进行采样。或者是从指定的区间中进行采样,采样个数可以通过参数指定:
data = [4,65,6,3,5,73,23,5,6]
result1 = np.random.choice(data,size=(2,3)) #从data中随机采样,生成2行3列的数组
result2 = np.random.choice(data,3) #从data中随机采样3个数据形成一个一维数组
result3 = np.random.choice(10,3) #从0-10之间随机取3个值
2
3
4
# np.random.shuffle
把原来数组的元素的位置打乱。示例代码如下:
a = np.arange(10)
np.random.shuffle(a) #将a的元素的位置都会进行随机更换
2
- 练习
"""
@Author :frx
@Time :2021/11/25 11:39
@Version :1.0
"""
import numpy as np
np.random.seed(1)
num=np.random.rand()
print(num)
num1=np.random.rand(2,3)
print(num1)
num2=np.random.randn() #标准正态分布的数
print(num2)
data=np.arange(5)
print(data)
data1=np.random.choice(data,size=(3,4))
print(data1)
data=np.arange(10)
print(data)
np.random.shuffle(data) #随机打乱 没有返回值
print(data)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 更多:
更多的random模块的文档,请参考Numpy的官方文档:https://docs.scipy.org/doc/numpy/reference/routines.random.html (opens new window)
# Axis理解
之前的课程中,为了方便大家理解,我们说axis=0代表的是行,axis=1代表的是列。但其实不是这么简单理解的。这里我们专门用一节来解释一下这个axis轴的概念。
简单来说, 最外面的括号代表着 axis=0,依次往里的括号对应的 axis 的计数就依次加 1。什么意思呢?下面再来解释一下。
 最外面的括号就是
最外面的括号就是axis=0,里面两个子括号axis=1。
操作方式:如果指定轴进行相关的操作,那么他会使用轴下的每个直接子元素的第0个,第1个,第2个...分别进行相关的操作。
现在我们用刚刚理解的方式来做几个操作。比如现在有一个二维的数组:
x = np.array([[0,1],[2,3]])
求
x数组在axis=0和axis=1两种情况下的和:>>> x.sum(axis=0) array([2, 4])1
2为什么得到的是[2,4]呢,原因是我们按照
axis=0的方式进行相加,那么就会把最外面轴下的所有直接子元素中的第0个位置进行相加,第1个位置进行相加...依此类推,得到的就是0+2以及2+3,然后进行相加,得到的结果就是[2,4]。>>> x.sum(axis=1) array([1, 5])1
2因为我们按照
axis=1的方式进行相加,那么就会把轴为1里面的元素拿出来进行求和,得到的就是0,1,进行相加为1,以及2,3进行相加为5,所以最终结果就是[1,5]了。用
np.max求axis=0和axis=1两种情况下的最大值:
>>> np.random.seed(100)
>>> x = np.random.randint(0,10,size=(3,5))
>>> x.max(axis=0)
array([8, 8, 3, 7, 8])
2
3
4
因为我们是按照axis=0进行求最大值,那么就会在最外面轴里面找直接子元素,然后将每个子元素的第0个值放在一起求最大值,将第1个值放在一起求最大值,以此类推。而如果axis=1,那么就是拿到每个直接子元素,然后求每个子元素中的最大值:
>>> x.max(axis=1)
array([8, 5, 8])
2
用
np.delete在axis=0和axis=1两种情况下删除元素:>>> np.delete(x,0,axis=0) array([[2, 3]])1
2np.delete是个例外。我们按照axis=0的方式进行删除,那么他会首先找到最外面的括号下的直接子元素中的第0个,然后删掉,剩下最后一行的数据。>>> np.delete(x,0,axis=1) array([[1], [3]])1
2
3同理,如果我们按照
axis=1进行删除,那么会把第一列的数据删掉。
- 练习
"""
@Author :frx
@Time :2021/11/26 9:48
@Version :1.0
"""
import numpy as np
a=np.arange(0,4).reshape(2,2)
print(a)
# [[0 1]
# [2 3]]
print(a.sum(axis=0))
# [2 4]
print(a.sum(axis=1))
# [1 5]
x=np.arange(12).reshape(2,6)
print(x)
# [[ 0 1 2 3 4 5]
# [ 6 7 8 9 10 11]]
print(x.max(axis=0))
# [ 6 7 8 9 10 11]
print(x.max(axis=1))
# [ 5 11]
print(np.delete(x,0,axis=0))
# [[ 6 7 8 9 10 11]]
y=np.arange(24).reshape(2,2,6)
print(y)
# [[12 13 14 15 16 17]
# [18 19 20 21 22 23]]]
print(y.max(axis=0))
# [[12 13 14 15 16 17]
# [18 19 20 21 22 23]]]
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
总结:
- 最外面的括号代表着axis=0,依次往里面的括号对应的axis的计数就依次加1。
- 操作方式:如果指定轴进行相关的操作,那么它会使用轴下的每个直接子元素的第0个,第1个,第2个...分别进行相关的操作。
- np.delete,是直接删除指定轴下的第几个直接子元素。
# 三维以上数组
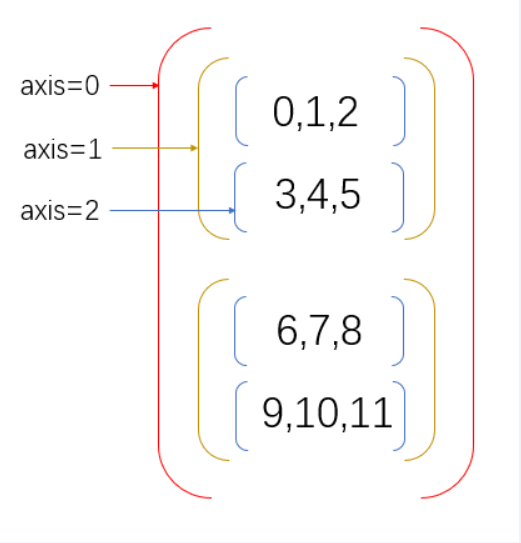
按照之前的理论,如果以上数组按照axis=0的方式进行相加,得到的结果如下:
 如果是按照
如果是按照axis=1的方式进行相加,得到的结果如下:
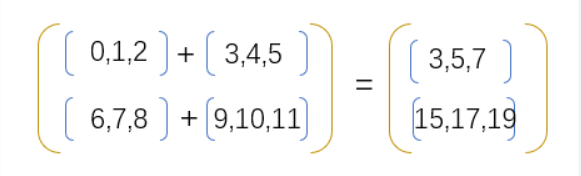
# 通用函数
# 一元函数
| 函数 | 描述 |
|---|---|
| np.abs | 绝对值 |
| np.sqrt | 开根 |
| np.square | 平方 |
| np.exp | 计算指数(e^x) |
| np.log,np.log10,np.log2,np.log1p | 求以e为底,以10为低,以2为低,以(1+x)为底的对数 |
| np.sign | 将数组中的值标签化,大于0的变成1,等于0的变成0,小于0的变成-1 |
| np.ceil | 朝着无穷大的方向取整,比如5.1会变成6,-6.3会变成-6 |
| np.floor | 朝着负无穷大方向取证,比如5.1会变成5,-6.3会变成-7 |
| np.rint,np.round | 返回四舍五入后的值 |
| np.modf | 将整数和小数分隔开来形成两个数组 |
| np.isnan | 判断是否是nan |
| np.isinf | 判断是否是inf |
| np.cos,np.cosh,np.sin,np.sinh,np.tan,np.tanh | 三角函数 |
| np.arccos,np.arcsin,np.arctan | 反三角函数 |
# 二元函数
| 函数 | 描述 |
|---|---|
| np.add | 加法运算(即1+1=2),相当于+ |
| np.subtract | 减法运算(即3-2=1),相当于- |
| np.negative | 负数运算(即-2),相当于加个负号 |
| np.multiply | 乘法运算(即2*3=6),相当于* |
| np.divide | 除法运算(即3/2=1.5),相当于/ |
| np.floor_divide | 取整运算,相当于// |
| np.mod | 取余运算,相当于% |
| greater,greater_equal,less,less_equal,equal,not_equal | >,>=,<,<=,=,!=的函数表达式 |
| logical_and | &的函数表达式 |
| logical_or | |的函数表达式 |
# 聚合函数
| 函数名称 | NAN安全版本 | 描述 |
|---|---|---|
| np.sum | np.nansum | 计算元素的和 |
| np.prod | np.nanprod | 计算元素的积 |
| np.mean | np.nanmean | 计算元素的平均值 |
| np.std | np.nanstd | 计算元素的标准差 |
| np.var | np.nanvar | 计算元素的方差 |
| np.min | np.nanmin | 计算元素的最小值 |
| np.max | np.nanmax | 计算元素的最大值 |
| np.argmin | np.nanargmin | 找出最小值的索引 |
| np.argmax | np.nanargmax | 找出最大值的索引 |
| np.median | np.nanmedian | 计算元素的中位数 |
使用np.sum或者是a.sum即可实现。并且在使用的时候,可以指定具体哪个轴。同样Python中也内置了sum函数,但是Python内置的sum函数执行效率没有np.sum那么高,可以通过以下代码测试了解到:
a = np.random.rand(1000000)
%timeit sum(a) #使用Python内置的sum函数求总和,看下所花费的时间
%timeit np.sum(a) #使用Numpy的sum函数求和,看下所花费的时间
2
3
# 布尔数组的函数
| 函数名称 | 描述 |
|---|---|
| np.any | 验证任何一个元素是否为真 |
| np.all | 验证所有元素是否为真 |
比如想看下数组中是不是所有元素都为0,那么可以通过以下代码来实现:
np.all(a==0)
# 或者是
(a==0).all()
2
3
比如我们想要看数组中是否有等于0的数,那么可以通过以下代码来实现:
np.any(a==0)
# 或者是
(a==0).any()
2
3
# 排序
np.sort:指定轴进行排序。默认是使用数组的最后一个轴进行排序。a = np.random.randint(0,10,size=(3,5)) b = np.sort(a) #按照行进行排序,因为最后一个轴是1,那么就是将最里面的元素进行排序。 c = np.sort(a,axis=0) #按照列进行排序,因为指定了axis=01
2
3还有
ndarray.sort(),这个方法会直接影响到原来的数组,而不是返回一个新的排序后的数组。np.argsort:返回排序后的下标值。示例代码如下:np.argsort(a) #默认也是使用最后的一个轴来进行排序。1降序排序:
np.sort默认会采用升序排序。如果我们想采用降序排序。那么可以采用以下方案来实现:# 1. 使用负号 -np.sort(-a) # 2. 使用sort和argsort以及take indexes = np.argsort(-a) #排序后的结果就是降序的 np.take(a,indexes) #从a中根据下标提取相应的元素1
2
3
4
5
6
# 其他函数补充
np.apply_along_axis:沿着某个轴执行指定的函数。示例代码如下:# 求数组a按行求均值,并且要去掉最大值和最小值。 np.apply_along_axis(lambda x:x[(x != x.max()) & (x != x.min())].mean(),axis=1,arr=a)1
2np.linspace:用来将指定区间内的值平均分成多少份。示例代码如下:# 将0-1分成12分,生成一个数组 np.linspace(0,1,12)1
2np.unique:返回数组中的唯一值。# 返回数组a中的唯一值,并且会返回每个唯一值出现的次数。 np.unique(a,return_counts=True)1
2
3
# 更多:
https://docs.scipy.org/doc/numpy/reference/index.html (opens new window)
# Numpy练习题
一、查看Numpy的版本号:
import numpy as np
print(np.__version__)
2
二、如何创建一个所有值都是False的布尔类型的数组:
np.full((3,3),False,dtype=np.bool)
三、将一个有10个数的数组的形状进行转换:
arr = np.arange(10)
arr.reshape(2,5) #转换成(2,5)的数组
arr[:,np.newaxis] #转换成(10,1)的数组
2
3
np.newaxis所处的位置,会变成1。比如:
arr = np.random.randint(0,10,size=(10,2))
arr1 = arr[:,np.newaxis,:]
print(arr1.shape)
# 结果是(10,1,2),因为np.newaxis所在的位置是1
2
3
4
四、将数组中所有偶数都替换成0(改变原来数组和不改变原来数组两种方式实现):
arr = np.random.randint(0,10,size=(3,3))
# 1. 不改变原来数组
arr1 = np.where(arr%2==0,0,arr)
print(arr1)
# 2. 改变原来数组
arr[arr%2==0] = 0
2
3
4
5
6
五、创建一个一维且有10个数的数组,元素是从0-1之间,但是不包含0和1:
arr = np.linspace(0,1,12)[1:-1]
其中的linspace是在起始值和结束值之间平均的获取指定个数的数。比如以上就是从0-1之间获取12个数组。
六、求以下数组大于等于5并且小于等于10的数组:
a = np.arange(15)
# 方法1
index = np.where((a >= 5) & (a <= 10))
a[index]
# 方法2:
index = np.where(np.logical_and(a>=5, a<=10))
a[index]
#> (array([6, 9, 10]),)
# 方法3:
a[(a >= 5) & (a <= 10)]
2
3
4
5
6
7
8
9
10
11
12
七、将一个二维数组的行和列分别进行逆向:
a = np.arange(15).reshape(3,5)
# 反转行
a1 = a[::-1] #里面传一个数进去(没有出现逗号),代表的是只对行进行操作
# 反转列
a2 = a[:,::-1] #里面传两个数进去,第一个是所有的行,第二个就是针对所有的列,但是取值的方向是从后面到前面。
2
3
4
5
八、如何将科学计数法转换为浮点类型打印:
# set_printoptions用来设置打印的时候的一些配置和选项
# 将suppress设置为True,就不会显示成科学计数法了,并且通过precision来控制小数点后要保留几位
np.set_printoptions(suppress=True,precision=6)
rand_arr = np.random.random([3,3])/1e3
print(rand_arr)
2
3
4
5
九、获取一个数组中唯一的元素:
arr = np.random.randint(0,20,(10,10))
np.unique(arr)
2
十、获取一个数组中唯一的元素个数的排行:
arr = np.random.randint(0,20,(10,10))
np.unique(arr,return_counts=True)
2
十一、如何找到数组中每行的最大值:
# 解决方案1:
np.random.seed(100)
a = np.random.randint(1,10, [5,3])
print(a)
print("="*30)
print(np.amax(a,axis=1))
# 解决方案2:
print(np.apply_along_axis(np.max,arr=a,axis=1))
2
3
4
5
6
7
8
9
十二、如何按照行求最小值与最大值相除的结果:
np.random.seed(100)
a = np.random.randint(1,10, [5,3])
np.apply_along_axis(lambda x: np.min(x)/np.max(x),arr=a,axis=1)
2
3
十三、判断两个数组是否完全相等:
a = np.array([0,1,2])
b = np.arange(3)
(a == b).all()
2
3
十四、设置一个数组不能修改值:
a = np.zeros((2,2))
a.flags.writable = False
a[0] = 1
2
3
十五、找到数组中离某个元素的最近的值:
np.random.seed(100)
Z = np.random.uniform(0,1,10)
z = 0.5
m = Z[np.abs(Z - z).argmin()]
print(m)
2
3
4
5